注意
想法及时记录,实现可以待做。
Map
Map常用有哪些呢?如图所示:
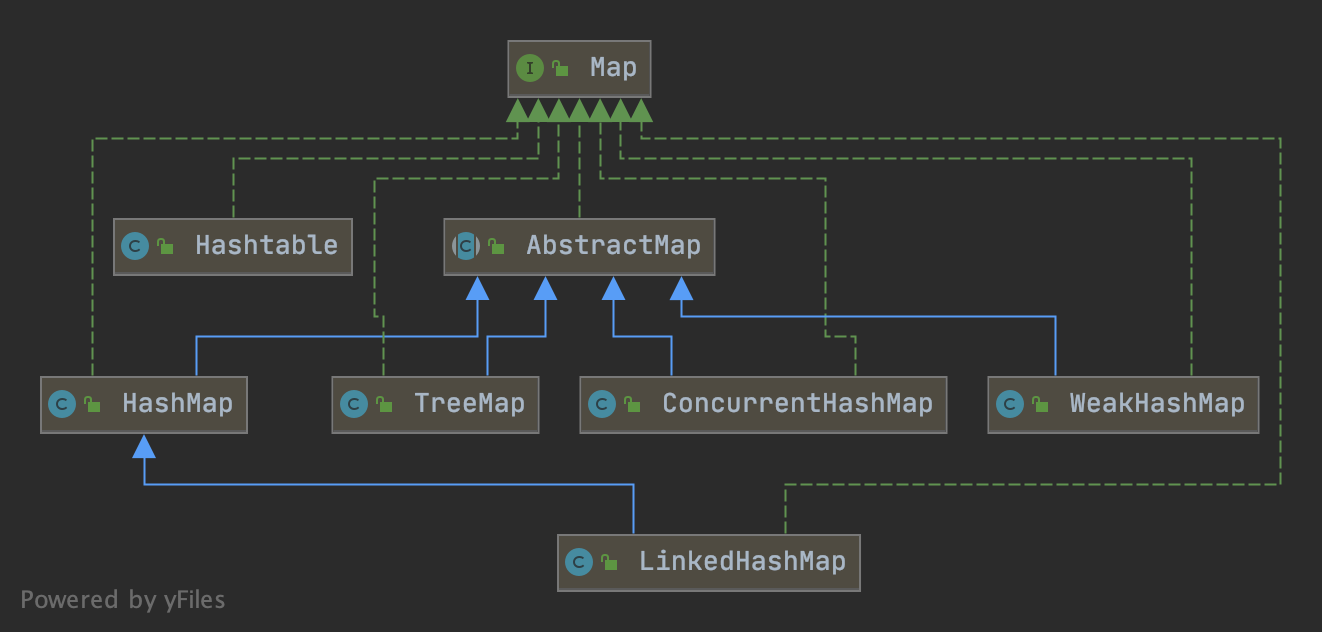
简介
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。
HashMap是Java中用于映射(键值对)处理的数据类型。本文主要基于Java8来做介绍,底层的数据结构由数组与链表和红黑树组成。
HashMap允许键和值为null,如果键为null,此时的hash码是0,这点要注意下。作为键值对映射的数据结构,只管映射关系,没有处理顺序,专注于映射的处理。
所以LinkedHashMap在HashMap的基础之上,维护了一条双向链表,支持顺序访问。
它的复杂度一般来说是常数级,也就是O(1),但是也不绝对,如果有hash碰撞了,有可能退化为O(n)或者是O(log n)。
如果不熟悉HashMap,可以看Java8之HashMap介绍
分析
本文主要介绍LinkedHashMap是如何有序的,并且里面的几个特殊方法的实现目的。
特别注意
/**
* 双向链表的头节点
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* 双向链表的尾节点
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* 这个字段是final,从构造器中传入,默认是fasle,按照插入顺序,如果要访问顺序,则设置true
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;
/**
* 继承HashMap的Node,Entry是LinkedHashMap实现双向链表的关键
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
// 双向链表的指向
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
插入
LinkedHashMap是继承HashMap,其中插入的核心方法还是用的HashMap,只是构建新节点不一样,LinkedHashMap重写了newNode方法
// HashMap的方法,LinkedHashMap直接使用
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// LinkedHashMap重写了这个方法
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
...
}
// LinkedHashMap的实现
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
// 构造成LinkedHashMap的内部的Entry结构的节点
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 新节点加入双端链表的尾部
linkNodeLast(p);
return p;
}
// 这个方法才是构造双向链表的关键,用的正是Entry的before和after指向
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
// 局部变量,获取双向链表的全局尾节点的指向
LinkedHashMap.Entry<K,V> last = tail;
// 新节点指向全局的尾节点
tail = p;
// 尾节点如果为null,说明双向链表是空的,上面已经将新的节点指向尾节点了,这里还要将新节点指向头节点
if (last == null)
head = p;
else {
// 新节点的前驱指向之前的尾节点,之前的尾节点的后继指向新节点
p.before = last;
last.after = p;
}
}
特殊方法
// 在HashMap中,插入和删除有下面回调三个方法是空实现,他们在LinkedHashMap中有具体实现
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
// HashMap中,删除节点的时候,会调用这个方法,LinkedHashMap要处理双向节点的指向问题
void afterNodeRemoval(Node<K,V> e) { // unlink
// 局部变量保存需要删除的节点,删除节点的前、后指向
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 局部变量节点的前驱后继节点置为null
p.before = p.after = null;
// 说明被删除的是头节点
if (b == null)
// 那么将后继节点作为头节点
head = a;
else
// 否则直接将后继节点指向前驱结点的后继方向,这样两者中间的节点联系即可断开
b.after = a;
// 说明被删除的是尾节点
if (a == null)
tail = b;
else
a.before = b;
}
// 插入节点后,双向链表的回调操作
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 是否移除最近最少被访问的节点,这里很重要!可以实现各种策略的缓存。
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
// 调用HashMap的方法删除节点
removeNode(hash(key), key, null, false, true);
}
}
// LinkedHashMap提供的protected方法,一看就知道子类可以根据需要重写
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
// 访问节点的时候,会调用这个方法。
// 不过如果是默认的插入顺序,这个方法没啥执行的。重点要看的是 访问顺序的时候,它是将访问的节点移动到链表尾部。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 访问顺序,也即构造器传的是true,并且 访问的节点不在尾部
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
// 访问的节点加在链表的尾部
p.before = last;
last.after = p;
}
// 访问的这个节点,指向全局的尾部变量
tail = p;
// 修改次数增加
++modCount;
}
}
查询
/**
* LinkedHashMap重写了get方法,没有用HashMap的实现,主要是因为访问是有序的。
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*/
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
// 很关键,默认是false,插入顺序;
// 如果是true,就是访问顺序,这里会将访问的Node移到双向链表的尾部,分析可以看上部分说明。
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
