注意
想法及时记录,实现可以待做。
简介
队列是一种先进先出的数据结构,从队首取值,从队尾写入值。java中的队列基础的接口有以下几类:
| 方法 | 抛出异常 | 返回值 |
|---|---|---|
| 插入 | add | offer |
| 获取并移除队首 | remove | poll |
| 获取队首 | element | peek |
BlockingQueue的UML类图如图所示:
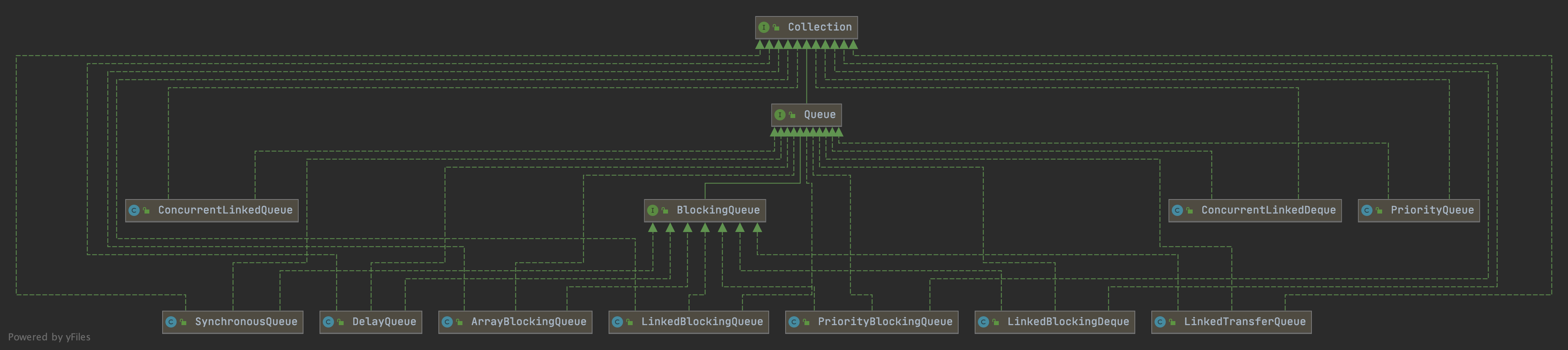
SynchronousQueue是BlockingQueue的一种实现,但是它很特殊,主要有:
- 没有容量,从源码可以看,永远为空。
- 构造的时候,可以设置策略,公平或者非公平模式。
- 生产数据后一定会等待被消费,否则生产就会被阻塞。
SynchronousQueue这种队列适合的场景就是任务处理很快速,否则一方要么消费阻塞,要么生产阻塞,都不是特别好的情况。
JUC中Executors工厂中提供的newCachedThreadPool方法,队列使用的就是SynchronousQueue。
那为什么newCachedThreadPool会选用SynchronousQueue而不是其他的BlockingQueue呢,因为通过TPE可以知道,线程池的工作流程是先使用核心线程,然后入队,最后根据最大线程数增加线程,增大消费能力。
对于newCachedThreadPool的构造方法可以知道,核心线程数为0,最大线程数为一个很大的值,线程存活时间60s,那么意味着,如果使用其他的BlockingQueue,一定会有容量设置,也就是说,新增的任务直接入队,而此时,并没有线程来处理任务。
那么,如果使用没有容量的其他队列呢,如果真这么用,那还要阻塞队列干嘛,用线程池干嘛,都没达到线程复用的效果,最后只能是通过最大线程数来新建线程处理任务,处理完线程便销毁,无法持续从队列获取任务继续工作。
所以,一定需要使用的这种队列效果是,队列可以没有容量,但是通过最大线程数创建线程后,创建好的线程持续的去队列获取任务,线程不会被销毁,达到线程复用的目的。
这种不就是SynchronousQueue的特点嘛,添加的任务,由于没有核心线程数,直接入队,由于队列大小为0,根据最大线程数创建新的线程,然后将队列的任务进行匹配,此时这个队列维护的就是一堆需要匹配的线程任务,所以这种任务一定要处理很及时很迅速,而且通过线程存活时间机制,能在60s的时间内避免线程数过多引起系统不稳定。
当然,也要注意的是,使用不当,高并发下,有的任务处理不及时,是很有可能在60s的线程存活时间内,将线程创建的资源超过系统的限制,从而引起系统不稳定。
组成介绍
// cpu数量
static final int NCPUS = Runtime.getRuntime().availableProcessors();
/**
* 在超时阻塞前允许自旋的次数,cpu只有1个的,不用自旋,否则为32次
* The number of times to spin before blocking in timed waits.
* The value is empirically derived -- it works well across a
* variety of processors and OSes. Empirically, the best value
* seems not to vary with number of CPUs (beyond 2) so is just
* a constant.
*/
static final int maxTimedSpins = (NCPUS < 2) ? 0 : 32;
/**
* 没有超时的阻塞下,自旋的次数是超时的16倍
* The number of times to spin before blocking in untimed waits.
* This is greater than timed value because untimed waits spin
* faster since they don't need to check times on each spin.
*/
static final int maxUntimedSpins = maxTimedSpins * 16;
/**
* 针对有超时的情况,自旋了多少次后,如果剩余时间大于1000纳秒就使用带时间的LockSupport.parkNanos()这个方法
* The number of nanoseconds for which it is faster to spin
* rather than to use timed park. A rough estimate suffices.
*/
static final long spinForTimeoutThreshold = 1000L;
/**
* 传输器,构造的时候就决定哪种,公平模式,选队列;非公平模式,选栈。
* The transferer. Set only in constructor, but cannot be declared
* as final without further complicating serialization. Since
* this is accessed only at most once per public method, there
* isn't a noticeable performance penalty for using volatile
* instead of final here.
*/
private transient volatile Transferer<E> transferer;
关键内部类
// 抽象静态内部类,传输器,其中的方法用户线程间交换元素使用
abstract static class Transferer<E> {
abstract E transfer(E e, boolean timed, long nanos);
}
// 静态内部类,继承了上述的抽象类,实现了transfer方法,以栈的存储方式
static final class TransferStack<E> extends Transferer<E> {
// 栈中的节点的类型值
// 表示消费者,待完成
static final int REQUEST = 0;
// 表示生产者,待完成
static final int DATA = 1;
// 消费者与生产者正在匹配中,正在完成
static final int FULFILLING = 2;
/** Returns true if m has fulfilling bit set. */
static boolean isFulfilling(int m) { return (m & FULFILLING) != 0; }
// 栈中的节点
static final class SNode {
// 下一个节点
volatile SNode next;
// 匹配的节点
volatile SNode match;
// 等待的线程
volatile Thread waiter;
// 数据
Object item; // data; or null for REQUESTs
// 节点的类型,三者之一
int mode;
// Note: item and mode fields don't need to be volatile
// since they are always written before, and read after,
// other volatile/atomic operations.
}
// 栈顶节点
volatile SNode head;
/**
* Creates or resets fields of a node. Called only from transfer
* where the node to push on stack is lazily created and
* reused when possible to help reduce intervals between reads
* and CASes of head and to avoid surges of garbage when CASes
* to push nodes fail due to contention.
*/
static SNode snode(SNode s, Object e, SNode next, int mode) {
if (s == null) s = new SNode(e);
s.mode = mode;
s.next = next;
return s;
}
/**
* Returns true if node s is at head or there is an active
* fulfiller.
*/
boolean shouldSpin(SNode s) {
SNode h = head;
return (h == s || h == null || isFulfilling(h.mode));
}
/**
* Unlinks s from the stack.
*/
void clean(SNode s) {
s.item = null; // forget item
s.waiter = null; // forget thread
/*
* At worst we may need to traverse entire stack to unlink
* s. If there are multiple concurrent calls to clean, we
* might not see s if another thread has already removed
* it. But we can stop when we see any node known to
* follow s. We use s.next unless it too is cancelled, in
* which case we try the node one past. We don't check any
* further because we don't want to doubly traverse just to
* find sentinel.
*/
SNode past = s.next;
if (past != null && past.isCancelled())
past = past.next;
// Absorb cancelled nodes at head
SNode p;
while ((p = head) != null && p != past && p.isCancelled())
casHead(p, p.next);
// Unsplice embedded nodes
while (p != null && p != past) {
SNode n = p.next;
if (n != null && n.isCancelled())
p.casNext(n, n.next);
else
p = n;
}
}
}
// 静态内部类,继承了上述的抽象类,实现了transfer方法,以队列的存储方式
static final class TransferQueue<E> extends Transferer<E> {
// 队列中的节点
static final class QNode {
// 下一个节点
volatile QNode next; // next node in queue
// 存储的数据
volatile Object item; // CAS'ed to or from null
// 等待的线程
volatile Thread waiter; // to control park/unpark
// 入队或者出队,为true表示入队
final boolean isData;
QNode(Object item, boolean isData) {
this.item = item;
this.isData = isData;
}
}
// 队列的头节点
transient volatile QNode head;
// 队列的尾节点
transient volatile QNode tail;
/**
*
* Reference to a cancelled node that might not yet have been
* unlinked from queue because it was the last inserted node
* when it was cancelled.
*/
transient volatile QNode cleanMe;
// 默认构造器
TransferQueue() {
// 生成一个dummy节点
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
}
/**
* Gets rid of cancelled node s with original predecessor pred.
*/
void clean(QNode pred, QNode s) {
s.waiter = null; // forget thread
/*
* At any given time, exactly one node on list cannot be
* deleted -- the last inserted node. To accommodate this,
* if we cannot delete s, we save its predecessor as
* "cleanMe", deleting the previously saved version
* first. At least one of node s or the node previously
* saved can always be deleted, so this always terminates.
*/
while (pred.next == s) { // Return early if already unlinked
QNode h = head;
QNode hn = h.next; // Absorb cancelled first node as head
if (hn != null && hn.isCancelled()) {
advanceHead(h, hn);
continue;
}
QNode t = tail; // Ensure consistent read for tail
if (t == h)
return;
QNode tn = t.next;
if (t != tail)
continue;
if (tn != null) {
advanceTail(t, tn);
continue;
}
if (s != t) { // If not tail, try to unsplice
QNode sn = s.next;
if (sn == s || pred.casNext(s, sn))
return;
}
QNode dp = cleanMe;
if (dp != null) { // Try unlinking previous cancelled node
QNode d = dp.next;
QNode dn;
if (d == null || // d is gone or
d == dp || // d is off list or
!d.isCancelled() || // d not cancelled or
(d != t && // d not tail and
(dn = d.next) != null && // has successor
dn != d && // that is on list
dp.casNext(d, dn))) // d unspliced
casCleanMe(dp, null);
if (dp == pred)
return; // s is already saved node
} else if (casCleanMe(null, pred))
return; // Postpone cleaning s
}
}
}
构造方法
// 默认构造器,是非公平模式,以栈为存储方式
public SynchronousQueue() {
this(false);
}
// 构造的时候,可以选择公平方式,则是队列存储,非公平方式就是默认的方式,栈存储。
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
入队
// 数据入队,一直等待另一个线程接收这个数据
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// transfer方法,数据入队,没有超时机制,要一直等待
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
// e不为null,有超时设置,但是超时时间为0纳秒
return transferer.transfer(e, true, 0) != null;
}
出队
// 获取头节点,然后移除队列的头节点,如果没有数据,要一直等着另一个线程写入数据
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
public E poll() {
return transferer.transfer(null, true, 0);
}
TransferStack.transfer方法
入队和出队都有这个transfer方法,很明显这是个很核心的方法,里面一定会实现线程间的等待交换数据。
/**
* 以栈的存储方式,进行队列的入队和出队操作
* Puts or takes an item.
*/
@SuppressWarnings("unchecked")
E transfer(E e, boolean timed, long nanos) {
/*
* Basic algorithm is to loop trying one of three actions:
*
* 1. If apparently empty or already containing nodes of same
* mode, try to push node on stack and wait for a match,
* returning it, or null if cancelled.
*
* 2. If apparently containing node of complementary mode,
* try to push a fulfilling node on to stack, match
* with corresponding waiting node, pop both from
* stack, and return matched item. The matching or
* unlinking might not actually be necessary because of
* other threads performing action 3:
*
* 3. If top of stack already holds another fulfilling node,
* help it out by doing its match and/or pop
* operations, and then continue. The code for helping
* is essentially the same as for fulfilling, except
* that it doesn't return the item.
*/
SNode s = null; // constructed/reused as needed
// 根据e是否为null,决定这个节点是生产者还是消费者
int mode = (e == null) ? REQUEST : DATA;
// 自旋 + CAS
for (;;) {
// 栈顶节点
SNode h = head;
// 栈顶节点为null,或者栈顶的节点类型与当前数据是一致的
if (h == null || h.mode == mode) { // empty or same-mode
// 有超时,并且到期
if (timed && nanos <= 0) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {
// 更新栈顶节点为s,等待节点s匹配
SNode m = awaitFulfill(s, timed, nanos);
// 节点被取消 ,就做清除操作
if (m == s) { // wait was cancelled
clean(s);
return null;
}
// 栈顶节点不为null 并且栈顶的下一个节点是s,cas操作将节点s的下一个节点置为栈顶节点,这也就是说会h和s都出栈
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller
return (E) ((mode == REQUEST) ? m.item : s.item);
}
// 节点类型不一样,栈顶节点如果不是在匹配中
} else if (!isFulfilling(h.mode)) { // try to fulfill
// 取消了,cas将栈顶下一个节点设置为栈顶节点
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
// 入栈 s ,变为栈顶节点
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
// 循环匹配或者等待节点没了
for (;;) { // loop until matched or waiters disappear
// m是s的匹配节点
SNode m = s.next; // m is s's match
// 有其他线程匹配了,s这个节点就需要cas操作去掉
if (m == null) { // all waiters are gone
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}
// m的下一个节点是mn
SNode mn = m.next;
// m和s尝试匹配,成功,则将m和s都出栈,然后将mn置为栈顶
if (m.tryMatch(s)) {
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
// m和s没有匹配成功,则m出栈,mn作为值替换
s.casNext(m, mn); // help unlink
}
}
// 节点类型不一样,栈顶节点正在匹配中
} else { // help a fulfiller
// 栈顶的下一个节点m
SNode m = h.next; // m is h's match
// m已经被其他线程匹配了
if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node
else {
// 栈顶的下一个节点m的下一个
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}
}
}
/**
* 自旋或者阻塞,直到被节点匹配
* Spins/blocks until node s is matched by a fulfill operation.
*
* @param s the waiting node
* @param timed true if timed wait
* @param nanos timeout value
* @return matched node, or s if cancelled
*/
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
/*
* When a node/thread is about to block, it sets its waiter
* field and then rechecks state at least one more time
* before actually parking, thus covering race vs
* fulfiller noticing that waiter is non-null so should be
* woken.
*
* When invoked by nodes that appear at the point of call
* to be at the head of the stack, calls to park are
* preceded by spins to avoid blocking when producers and
* consumers are arriving very close in time. This can
* happen enough to bother only on multiprocessors.
*
* The order of checks for returning out of main loop
* reflects fact that interrupts have precedence over
* normal returns, which have precedence over
* timeouts. (So, on timeout, one last check for match is
* done before giving up.) Except that calls from untimed
* SynchronousQueue.{poll/offer} don't check interrupts
* and don't wait at all, so are trapped in transfer
* method rather than calling awaitFulfill.
*/
// 到期时间,如果有超时设置,则是当前时间+超时时间,否则为0,也即没有超时
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
// 自旋次数
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
// 开始进入自旋
for (;;) {
// 如果当前线程中断,则尝试清除节点
if (w.isInterrupted())
s.tryCancel();
// 如果匹配到了,直接返回值
SNode m = s.match;
if (m != null)
return m;
// 超时设置
if (timed) {
// 超时时间已经过了
nanos = deadline - System.nanoTime();
// 尝试清除节点
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
// 没有设置超时,或者超时还没有到时间,则开始自旋计数,直到次数为0
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0;
// 自旋结束后,如果等待线程为null,则将当前线程作为等待线程
else if (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
// 自旋结束后,如果等待线程不为null,且没有超时设置,那么直接阻塞,并等待其他线程唤醒
else if (!timed)
LockSupport.park(this);
// 自旋结束后,等待线程不为null,如果有超时设置,且时间超过阈值,那么就阻塞相应的设置时间
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
/**
* Tries to match node s to this node, if so, waking up thread.
* Fulfillers call tryMatch to identify their waiters.
* Waiters block until they have been matched.
*
* @param s the node to match
* @return true if successfully matched to s
*/
boolean tryMatch(SNode s) {
if (match == null &&
UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) {
Thread w = waiter;
if (w != null) { // waiters need at most one unpark
waiter = null;
LockSupport.unpark(w);
}
return true;
}
return match == s;
}
TransferQueue.transfer方法
入队和出队都有这个transfer方法,很明显这是个很核心的方法,里面一定会实现线程间的等待交换数据。
/**
* 以队列的存储方式,进行队列的入队和出队操作
* Puts or takes an item.
*/
@SuppressWarnings("unchecked")
E transfer(E e, boolean timed, long nanos) {
/* Basic algorithm is to loop trying to take either of
* two actions:
*
* 1. If queue apparently empty or holding same-mode nodes,
* try to add node to queue of waiters, wait to be
* fulfilled (or cancelled) and return matching item.
*
* 2. If queue apparently contains waiting items, and this
* call is of complementary mode, try to fulfill by CAS'ing
* item field of waiting node and dequeuing it, and then
* returning matching item.
*
* In each case, along the way, check for and try to help
* advance head and tail on behalf of other stalled/slow
* threads.
*
* The loop starts off with a null check guarding against
* seeing uninitialized head or tail values. This never
* happens in current SynchronousQueue, but could if
* callers held non-volatile/final ref to the
* transferer. The check is here anyway because it places
* null checks at top of loop, which is usually faster
* than having them implicitly interspersed.
*/
QNode s = null; // constructed/reused as needed
// 如果e不为null,则设置为true,表示入队;否则是出队
boolean isData = (e != null);
for (;;) {
QNode t = tail;
QNode h = head;
// 从构造器可以知道,如果初始化了,一定会有一个dummy节点,首尾节点一开始就是dummy节点
if (t == null || h == null) // saw uninitialized value
// 未初始化,等待初始化
continue; // spin
// 首尾节点相等或者尾节点与当前节点的状态一致,要么入队要么出队
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
// 再次校验数据一致,避免被其他线程修改
if (t != tail) // inconsistent read
continue;
// 尾节点有下一个节点,那么cas设置新的尾节点,然后重试
if (tn != null) { // lagging tail
advanceTail(t, tn);
continue;
}
// 超时,并且时间到,就直接返回null,不需要阻塞等待
if (timed && nanos <= 0) // can't wait
return null;
// s节点未null,则初始化s节点,如果e为null,则s不包含数据,出队;如果e不为null,则s数据为e,入队。
if (s == null)
s = new QNode(e, isData);
// 尾节点的next指向s节点
if (!t.casNext(null, s)) // failed to link in
continue;
// 尾节点指向s节点
advanceTail(t, s); // swing tail and wait
// 超时,则超时等待,否则挂起线程,等待其他线程唤醒
Object x = awaitFulfill(s, e, timed, nanos);
// 超时到期,或者挂起的线程被中断,返回的当前节点,则清除节点
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
// s节点还没有出队
if (!s.isOffList()) { // not already unlinked
// s为新的头节点
advanceHead(t, s); // unlink if head
//
if (x != null) // and forget fields
s.item = s;
//
s.waiter = null;
}
return (x != null) ? (E)x : e;
} else { // complementary-mode
// 首尾节点不相等,尾节点与当前节点的状态也不一致,两者一个入队一个出队
// 头节点的下一个节点
QNode m = h.next; // node to fulfill
// 再次校验节点,防止其他线程修改
if (t != tail || m == null || h != head)
continue; // inconsistent read
// 头节点的下一个节点m的值
Object x = m.item;
// m节点被匹配 或者 m节点被取消 或者 cas失败
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
// 队列头节点出队,然后重试
advanceHead(h, m); // dequeue and retry
continue;
}
// 匹配成功,设置新的头节点
advanceHead(h, m); // successfully fulfilled
// 将m的等待线程唤醒
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
/**
* Spins/blocks until node s is fulfilled.
*
* @param s the waiting node
* @param e the comparison value for checking match
* @param timed true if timed wait
* @param nanos timeout value
* @return matched item, or s if cancelled
*/
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
// 自旋次数
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
// 线程被中断了,则取消节点
if (w.isInterrupted())
s.tryCancel(e);
Object x = s.item;
if (x != e)
return x;
// 超时,也时间到了,也取消节点
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
// 自旋次数自减
if (spins > 0)
--spins;
// 节点的等待线程为null,那么当前线程作为等待线程
else if (s.waiter == null)
s.waiter = w;
// 没有超时,则阻塞等待另一个线程唤醒
else if (!timed)
LockSupport.park(this);
// 有超时,且时间超过阈值,则等待指定时间
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
参考
- SynchronousQueue 源码分析 (基于Java 8)
- 死磕 java集合之SynchronousQueue源码分析
- SynchronousQueue源码解析
- 【JUC】JDK1.8源码分析之SynchronousQueue(九)
- SynchronousQueue源码分析
